
This is a summary of my recent talk at ODSC East.
If you’ve been at ODSC East this year, there’s one acronym that you’ve probably heard in nearly every talk: it’s RAG. RAG is one of the most used techniques to enhance LLMs in production, but why is it so? And what are its weak points?
In this post, we will first describe what RAG is and how it works at a high level. We will then see what type of failures we may encounter, how they happen, and a few reasons that may trigger these issues. Next, we will look at a few tools to help us evaluate a RAG application in production. Last, we’re going to list a few techniques to enhance your RAG app and make it more capable in a variety of scenarios.
Let’s dive in.
Outline Link to heading
- What is RAG?
- Why should I use it?
- Failure modes
- Evaluation strategies
- Advanced flavors of RAG
- A word on finetuning
- Conclusion
What is RAG? Link to heading
RAG stands for Retrieval Augmented Generation, which can be explained as: “A technique to augment LLM’s knowledge beyond its training data by retrieving contextual information before a generating an answer.”

RAG is a technique that works best for question-answering tasks, such as chatbots or similar knowledge extraction applications. This means that the user of a RAG app is a user who needs an answer to a question.
The first step of RAG is to take the question and hand it over to a component called retriever. A retriever is any system that, given a question, can find data relevant to the question within a vast dataset, be it text, images, rows in a DB, or anything else.
When implementing RAG, many developers think immediately that a vector database is necessary for retrieval. While vector databases such as Qdrant, ChromaDB, Weaviate and so on, are great for retrieval in some applications, they’re not the only option. Keyword-based algorithms such as Elasticsearch BM25 or TF-IDF can be used as retrievers in a RAG application, and you can even go as far as using a web search engine API, such as Google or Bing. Anything that is given a question and can return information relevant to the question can be used here.
Once our retriever sifted through all the data and returned a few relevant snippets of context, the question and the context are assembled into a RAG prompt. It looks like this:
Read the text below and answer the question at the bottom.
Text: [all the text found by the retriever]
Question: [the user's question]
This prompt is then fed to the last component, called a generator. A generator is any system that, given a prompt, can answer the question that it contains. In practice, “generator” is an umbrella term for any LLM, be it behind an API like GPT-3.5 or running locally, such as a Llama model. The generator receives the prompt, reads and understands it, and then writes down an answer that can be given back to the user, closing the loop.
Why should I use it? Link to heading
There are three main benefits of using a RAG architecture for your LLM apps instead of querying the LLM directly.
-
Reduces hallucinations. The RAG prompt contains the answer to the user’s question together with the question, so the LLM doesn’t need to know the answer, but it only needs to read the prompt and rephrase a bit of its content.
-
Allows access to fresh data. RAG makes LLMs capable of reasoning about data that wasn’t present in their training set, such as highly volatile figures, news, forecasts, and so on.
-
Increases transparency. The retrieval step is much easier to inspect than LLM’s inference process, so it’s far easier to spot and fact-check any answer the LLM provides.
To understand these points better, let’s see an example.
A weather chatbot Link to heading
We’re making a chatbot for a weather forecast app. Suppose the user asks an LLM directly, “Is it going to rain in Lisbon tomorrow morning?”. In that case, the LLM will make up a random answer because it obviously didn’t have tomorrow’s weather forecast for Lisbon in its training set and knows nothing about it.
When an LLM is queried with a direct question, it will use its internal knowledge to answer it. LLMs have read the entire Internet during their training phase, so they learned that whenever they saw a line such as “What’s the capital of France?”, the string “Paris” always appeared among the following few words. So when a user asks the same question, the answer will likely be “Paris”.
This “recalling from memory” process works for well-known facts but is not always practical. For more nuanced questions or something that the LLM hasn’t seen during training, it often fails: in an attempt to answer the question, the LLM will make up a response that is not based on any real source. This is called a hallucination, one of LLMs’ most common and feared failure modes.
RAG helps prevent hallucinations because, in the RAG prompt, the question and all the data needed to answer it are explicitly given to the LLM. For our weather chatbot, the retriever will first do a Google search and find some data. Then, we will put together the RAG prompt. The result will look like this:
Read the text below and answer the question at the bottom.
Text: According to the weather forecast, the weather in Lisbon tomorrow
is expected to be mostly sunny, with a high of 18°C and a low of 11°C.
There is a 25% chance of showers in the evening.
Question: Is it going to rain in Lisbon tomorrow morning?
Now, it’s clear that the LLM doesn’t have to recall anything about the weather in Lisbon from its memory because the prompt already contains the answer. The LLM only needs to rephrase the context. This makes the task much simpler and drastically reduces the chances of hallucinations.
In fact, RAG is the only way to build an LLM-powered system that can answer a question like this with any confidence at all. Retraining an LLM every morning with the forecast for the day would be a lot more wasteful, require a ton of data, and won’t return consistent results. Imagine if we were making a chatbot that gives you figures from the stock market!
In addition, a weather chatbot built with RAG can be fact-checked. If users have access to the web pages that the retriever found, they can check the pages directly when the results are not convincing, which helps build trust in the application.
A real-world example Link to heading
If you want to compare a well-implemented RAG system with a plain LLM, you can put ChatGPT (the free version, powered by GPT-3.5) and Perplexity to the test. ChatGPT does not implement RAG, while Perplexity is one of the most effective implementations existing today.
Let’s ask both: “Where does ODSC East 2024 take place?”
ChatGPT says:

While Perplexity says:
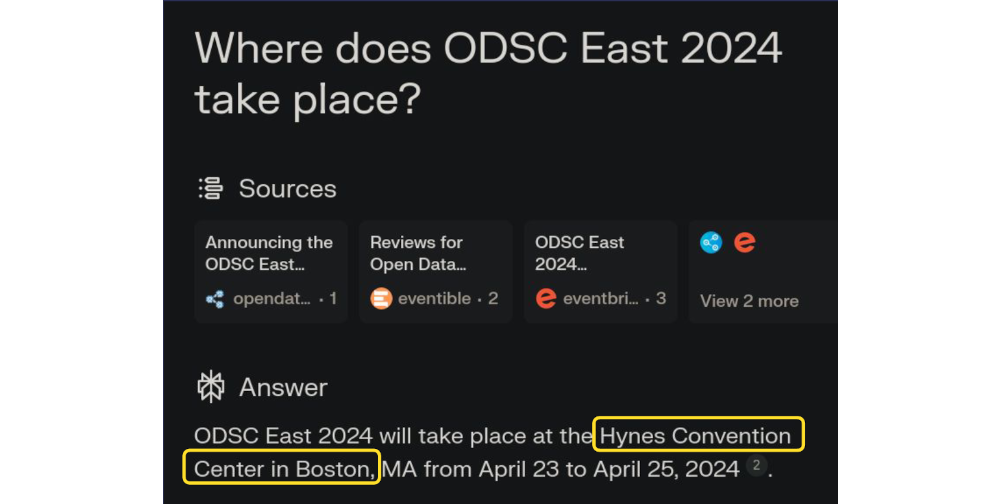
Note how ChatGPT clearly says that it doesn’t know: this is better than many other LLMs, which would just make up a place and date. On the contrary, Perplexity states some specific facts, and in case of doubt it’s easy to verify that it’s right by simply checking the sources above. Even just looking at the source’s URL can give users a lot more confidence in whether the answer is grounded.
Failure modes Link to heading
Now that we understand how RAG works, let’s see what can go wrong in the process.
As we’ve just described, a RAG app goes in two steps – retrieval and generation. Therefore, we can classify RAG failures into two broad categories:
-
Retrieval failures: The retriever component fails to find the correct context for the given question. The RAG prompt injects irrelevant noise into the prompt, which confuses the LLM and results in a wrong or unrelated answer.
-
Generation failures: The LLM fails to produce a correct answer even with a proper RAG prompt containing a question and all the data needed to answer it.
To understand them better, let’s pretend an imaginary user poses our application the following question about a little-known European microstate:
What was the official language of the Republic of Rose Island?
Here is what would happen in an ideal case:

First, the retriever searches the dataset (let’s imagine, in this case, Wikipedia) and returns a few snippets. The retriever did a good job here, and the snippets contain clearly stated information about the official language of Rose Island. The LLM reads these snippets, understands them, and replies to the user (correctly):
The official language of the Republic of Rose Island was Esperanto.
Retrieval failure Link to heading
What would happen if the retrieval step didn’t go as planned?

Here, the retriever finds some information about Rose Island, but none of the snippets contain any information about the official language. They only say where it was located, what happened to it, and so on. So the LLM, which knows nothing about this nation except what the prompt says, takes an educated guess and replies:
The official language of the Republic of Rose Island was Italian.
The wrong answer here is none of the LLM’s fault: the retriever is the component to blame.
When and why can retrieval fail? There are as many answers to this question as retrieval methods, so each should be inspected for its strengths and weaknesses. However there are a few reasons that are common to most of them.
-
The relevant data does not exist in the database. When the data does not exist, it’s impossible to retrieve it. Many retrieval techniques, however, give a relevance score to each result that they return, so filtering out low-relevance snippets may help mitigate the issue.
-
The retrieval algorithm is too naive to match a question with its relevant context. This is a common issue for keyword-based retrieval methods such as TF-IDF or BM25 (Elasticsearch). These algorithms can’t deal with synonims or resolve acronyms, so if the question and the relevant context don’t share the exact same words, the retrieval won’t work.
-
Embedding model (if used) is too small or unsuitable for the data. The data must be embedded before being searchable when doing a vector-based search. “Embedded” means that every snippet of context is associated with a list of numbers called an embedding. The quality of the embedding then determines the quality of the retrieval. If you embed your documents with a naive embedding model, or if you are dealing with a very specific domain such as narrow medical and legal niches, the embedding of your data won’t be able to represent their content precisely enough for the retrieval to be successful.
-
The data is not chunked properly (too big or too small chunks). Retrievers thrive on data that is chunked properly. Huge blocks of text will be found relevant to almost any question and will drown the LLM with information. Too small sentences or sentence fragments won’t carry enough context for the LLM to benefit from the retriever’s output. Proper chunking can be a huge lever to improve the quality of your retrieval.
-
The data and the question are in different languages. Keyword-based retrieval algorithms suffer from this issue the most because keywords in different languages rarely match. If you expect questions to come in a different language than the data you are retrieving from, consider adding a translation step or performing retrieval with a multilingual embedder instead.
One caveat with retrieval failures is that if you’re using a very powerful LLM such as GPT-4, sometimes your LLM is smart enough to understand that the retrieved context is incorrect and will discard it, hiding the failure. This means that it’s even more important to make sure retrieval is working well in isolation, something we will see in a moment.
Generation failure Link to heading
Assuming that retrieval was successful, what would happen if the LLM still hallucinated?

This is clearly an issue with our LLM: even when given all the correct data, the LLM still generated a wrong answer. Maybe our LLM doesn’t know that Esperanto is even a language? Or perhaps we’re using an LLM that doesn’t understand English well?
Naturally, each LLM will have different weak points that can trigger issues like these. Here are some common reasons why you may be getting generation failures.
-
The model is too small and can’t follow instructions well. When building in a resource-constrained environment (such as local smartphone apps or IoT), the choice of LLMs shrinks to just a few tiny models. However, the smaller the model, the less it will be able to understand natural language, and even when it does, it limits its ability to follow instructions. If you notice that your model consistently doesn’t pay enough attention to the question when answering it, consider switching to a larger or newer LLM.
-
The model knows too little about the domain to even understand the question. This can happen if your domain is highly specific, uses specific terminology, or relies on uncommon acronyms. Models are trained on general-purpose text, so they might not understand some questions without finetuning, which helps specify the meaning of the most critical key terms and acronyms. When the answers given by your model somewhat address the question but miss the point entirely and stay generic or hand-wavy, this is likely the case.
-
The model is not multilingual, but the questions and context may be. It’s essential that the model understands the question being asked in order to be able to answer it. The same is true for context: if the data found by the retriever is in a language that the LLM cannot understand, it won’t help it answer and might even confuse it further. Always make sure that your LLM understands the languages your users use.
-
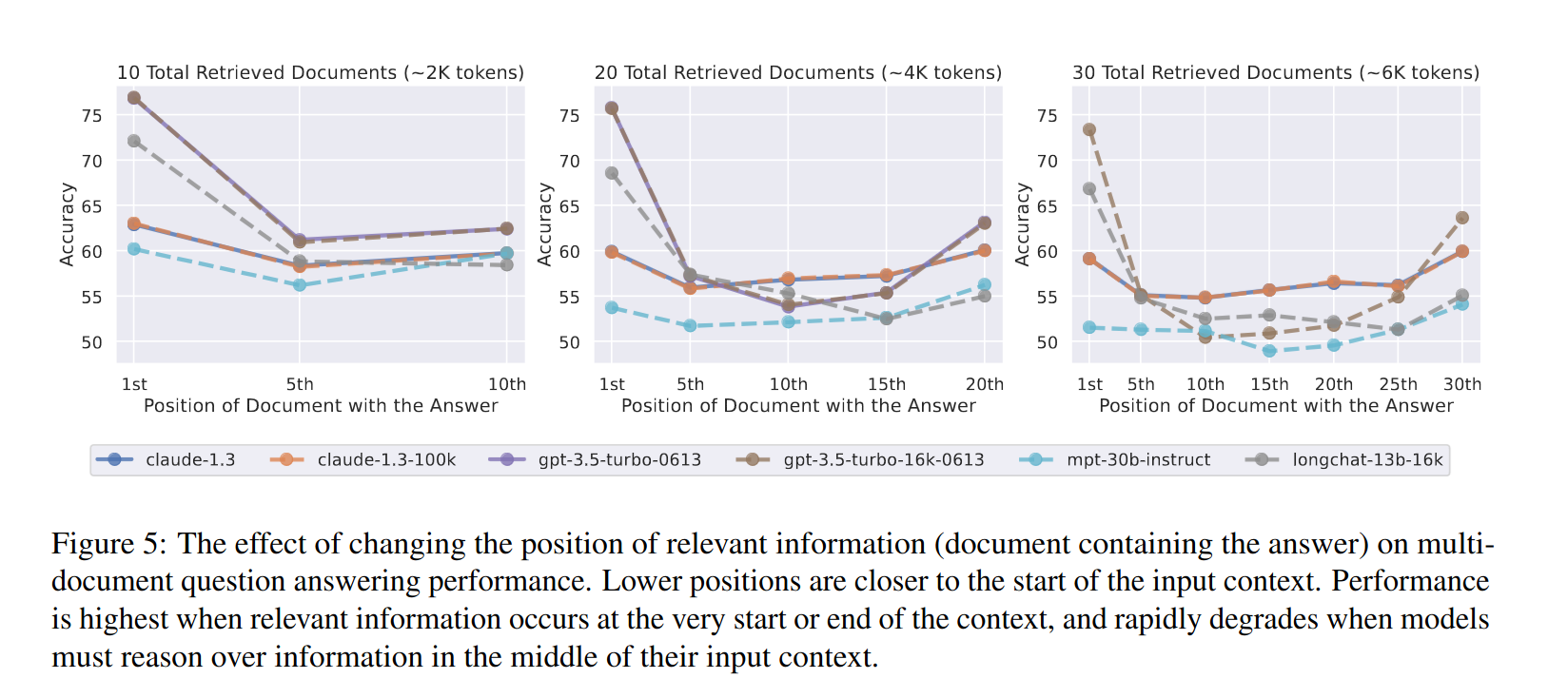
The RAG prompt is not built correctly. Some LLMs, especially older or smaller ones, may be very sensitive to how the prompt is built. If your model ignores part of the context or misses the question, the prompt might contain contradicting information, or it might be simply too large. LLMs are not always great at finding a needle in the haystack: if you are consistently building huge RAG prompts and you observe generation issues, consider cutting it back to help the LLM focus on the data that actually contains the answer.
Evaluation strategies Link to heading
Once we put our RAG system in production, we should keep an eye on its performance at scale. This is where evaluation frameworks come into play.
To properly evaluate the performance of RAG, it’s best to perform two evaluation steps:
-
Isolated Evaluation. Being a two-step process, failures at one stage can hide or mask the other, so it’s hard to understand where the failures originate from. To address this issue, evaluate the retrieval and generation separately: both must work well in isolation.
-
End to end evaluation. To ensure the system works well from start to finish, it’s best to evaluate it as a whole. End-to-end evaluation brings its own set of challenges, but it correlates more directly to the quality of the overall app.
Evaluating Retrieval Link to heading
Each retrieval method has its own state-of-the-art evaluation method and framework, so it’s usually best to refer to those.
For keyword-based retrieval algorithms such as TD-IDF, BM25, PageRank, and so on, evaluation is often done by checking the keywords match well. For this, you can use one of the many metrics used for this purpose: recall, precision, F1, MRR, MAP, …
For vector-based retrievers like vector DBs, the evaluation is more tricky because checking for matching keywords is not sufficient: the semantics of the question and the answer must evaluated for similarity. We are going to see some libraries that help with this when evaluating generation: in short, they use another LLM to judge the similarity or compute metrics like semantic similarity.
Evaluating Generation Link to heading
![]()
Evaluating an LLM’s answers to a question is still a developing art, and several libraries can help with the task. One commonly used framework is UpTrain, which implements an “LLM-as-a-judge” approach. This means that the answers given by an LLM are then evaluated by another LLM, normally a larger and more powerful model.
This approach has the benefit that responses are not simply checked strictly for the presence or absence of keywords but can be evaluated according to much more sophisticated criteria like completeness, conciseness, relevance, factual accuracy, conversation quality, and more.
This approach leads to a far more detailed view of what the LLM is good at and what aspects of the generation could or should be improved. The criteria to select depend strongly on the application: for example, in medical or legal apps, factual accuracy should be the primary metric to optimize for, while in customer support, user satisfaction and conversation quality are also essential. For personal assistants, it’s usually best to focus on conciseness, and so on.
End-to-end evaluation Link to heading
![]()
The evaluation of RAG systems end-to-end is also quite complex and can be implemented in many ways, depending on the aspect you wish to monitor. One of the simplest approaches is to focus on semantic similarity between the question and the final answer.
A popular framework that can be used for such high-level evaluation is RAGAS. In fact, RAGAS offers two interesting metrics:
-
Answer semantic similarity. This is computed simply by taking the cosine similarity between the answer and the ground truth.
-
Answer correctness. Answer correctness is defined as a weighted average of the semantic similarity and the F1 score between the generated answer and the ground truth. This metric is more oriented towards fact-based answers, where F1 can help ensure that relevant facts such as dates, names, and so on are explicitly stated.
On top of evaluation metrics, RAGAS also offers the capability to build synthetic evaluation datasets to evaluate your app against. Such datasets spare you the work-intensive process of building a real-world evaluation dataset with human-generated questions and answers but also trade high quality for volume and speed. If your domain is very specific or you need extreme quality, synthetic datasets might not be an option, but for most real-world apps, such datasets can save tons of labeling time and resources.
💡 I recently discovered an even more comprehensive framework for end-to-end evaluation called continuous-eval from Relari.ai, which focuses on modular evaluation of RAG pipelines. Check it out if you’re interested in this topic and RAGAS doesn’t offer enough flexibility for your use case.
![]()
Putting it all together Link to heading
![]()
Once you know how you want to evaluate your app, it’s time to put it together. A convenient framework for this step is Haystack, a Python open-source LLM framework focused on building RAG applications. Haystack is an excellent choice because it can be used through all stages of the application lifecycle, from prototyping to production, including evaluation.
Haystack supports several evaluation libraries including UpTrain, RAGAS and DeepEval. To understand more about how to implement and evaluate a RAG application with it, check out their tutorial about model evaluation here.
Advanced flavors of RAG Link to heading
Once our RAG app is ready and deployed in production, the natural next step is to look for ways to improve it even further. RAG is a very versatile technique, and many different flavors of “advanced RAG” have been experimented with, many more than I can list here. Depending on the situation, you may focus on different aspects, so let’s list some examples of tactics you can deploy to make your pipeline more powerful, context-aware, accurate, and so on.
Use multiple retrievers Link to heading
Sometimes, a RAG app needs access to vastly different types of data simultaneously. For example, a personal assistant might need access to the Internet, your Slack, your emails, your personal notes, and maybe even your pictures. Designing a single retriever that can handle data of so many different kinds is possible. Still, it can be a real challenge and require, in many cases, an entire data ingestion pipeline.
Instead of going that way, you can instead use multiple retrievers, each specialized to a specific subset of your data: for example, one retriever that browses the web, one that searches on Slack and in your emails, one that checks for relevant pictures.
When using many retrievers, however, it’s often best to introduce another step called reranking. A reranker double-checks that all the results returned by each retriever are actually relevant and sorts them again before the RAG prompt is built. Rerankers are usually much more precise than retrievers in assessing the relative importance of various snippets of context, so they can dramatically improve the quality of the pipeline. In exceptional cases, they can be helpful even in RAG apps with a single retriever.
Here is an example of such a pipeline built with Haystack.
Self-correction Link to heading
We mentioned that one of the most common evaluation strategies for RAG output is “LLM-as-a-judge”: the idea of using another LLM to evaluate the answer of the first. However, why use this technique only for evaluation?
Self-correcting RAG apps add one extra step at the end of the pipeline: they take the answer, pass it to a second LLM, and ask it to assess whether the answer is likely to be correct. If the check fails, the second LLM will provide some feedback on why it believes the answer is wrong, and this feedback will be given back to the first LLM to try answering another time until an agreement is reached.
Self-correcting LLMs can help improve the accuracy of the answers at the expense of more LLM calls per user question.
Agentic RAG Link to heading
In the LLMs field, the term “agent” or “agentic” is often used to identify systems that use LLMs to make decisions. In the case of a RAG application, this term refers to a system that does not always perform retrieval but decides whether to perform it by reading the question first.
For example, imagine we’re building a RAG app to help primary school children with their homework. When the question refers to topics like history or geography, RAG is very helpful to avoid hallucinations. However, if the question regards math, the retrieval step is entirely unnecessary, and it might even confuse the LLM by retrieving similar math problems with different answers.
Making your RAG app agentic is as simple as giving the question to an LLM before retrieval in a prompt such as:
Reply YES if the answer to this question should include facts and
figures, NO otherwise.
Question: What's the capital of France?
Then, retrieval is run or skipped depending on whether the answer is YES or NO.
This is the most basic version of agentic RAG. Some advanced LLMs can do better: they support so-called “function calling,” which means that they can tell you exactly how to invoke the retriever and even provide specific parameters instead of simply answering YES or NO.
For more information about function calling with LLMs, check out OpenAI’s documentation on the topic or the equivalent documentation of your LLM provider.
Multihop RAG Link to heading
Multihop RAG is an even more complex version of agentic RAG. Multihop pipelines often use chain-of-thought prompts, a type of prompt that looks like this:
You are a helpful and knowledgeable agent.
To answer questions, you'll need to go through multiple steps involving step-by-step
thinking and using a search engine to do web searches. The browser will respond with
snippets of text from web pages. When you are ready for a final answer, respond with
`Final Answer:`.
Use the following format:
- Question: the question to be answered
- Thought: Reason if you have the final answer. If yes, answer the question. If not,
find out the missing information needed to answer it.
- Search Query: the query for the search engine
- Observation: the search engine will respond with the results
- Final Answer: the final answer to the question, make it short (1-5 words)
Thought, Search Query, and Observation steps can be repeated multiple times, but
sometimes, we can find an answer in the first pass.
---
- Question: "Was the capital of France founded earlier than the discovery of America?"
- Thought:
This prompt is very complex, so let’s break it down:
- The LLM reads the question and decides which information to retrieve.
- The LLM returns a query for the search engine (or a retriever of our choice).
- Retrieval is run with the query the LLM provided, and the resulting context is appended to the original prompt.
- The entire prompt is returned to the LLM, which reads it, follows all the reasoning it did in the previous steps, and decides whether to do another search or reply to the user.
Multihop RAG is used for autonomous exploration of a topic, but it can be very expensive because many LLM calls are performed, and the prompts tend to become really long really quickly. The process can also take quite some time, so it’s not suitable for low-latency applications. However, the idea is quite powerful, and it can be adapted into other forms.
A word on finetuning Link to heading
It’s important to remember that finetuning is not an alternative to RAG. Finetuning can and should be used together with RAG on very complex domains, such as medical or legal.
When people think about finetuning, they usually focus on finetuning the LLM. In RAG, though, it is not only the LLM that needs to understand the question: it’s crucial that the retriever understands it well, too! This means the embedding model needs finetuning as much as the LLM. Finetuning your embedding models, and in some cases also your reranker, can improve the effectiveness of your RAG by orders of magnitude. Such a finetune often requires only a fraction of the training data, so it’s well worth the investment.
Finetuning the LLM is also necessary if you need to alter its behavior in production, such as making it more colloquial, more concise, or stick to a specific voice. Prompt engineering can also achieve these effects, but it’s often more brittle and can be more easily worked around. Finetuning the LLM has a much more powerful and lasting effect.
Conclusion Link to heading
RAG is a vast topic that could fill books: this was only an overview of some of the most important concepts to remember when working on a RAG application. For more on this topic, check out my other blog posts and stay tuned for future talks!